MeiTian Historical Data Management
An EB-era foundation for enterprise historical data: multi-source ingestion, copy data lake, hot/cold tiering and compliant archiving.
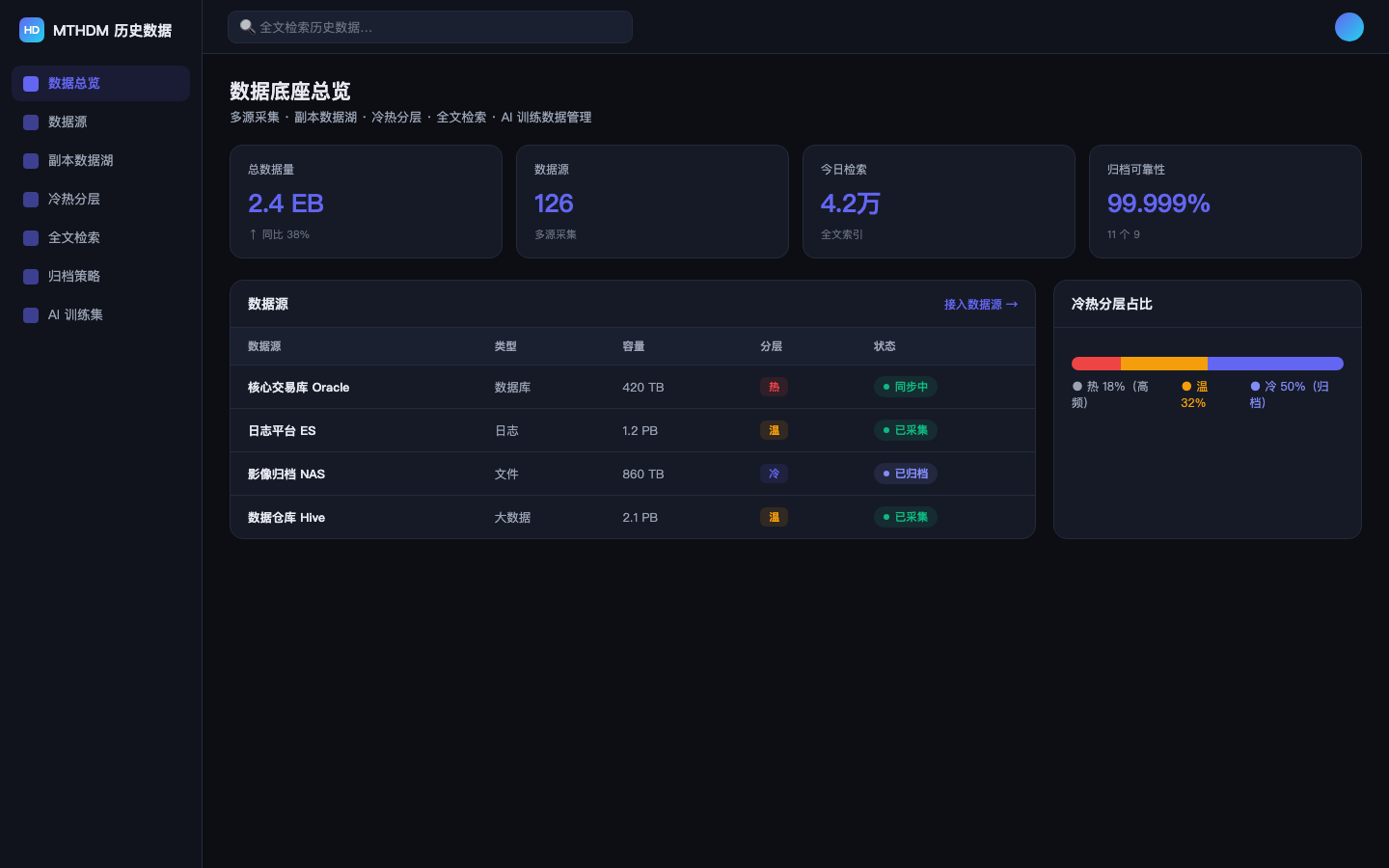
What MeiTian Historical Data Management does
MeiTian Historical Data Management is an EB-scale foundation for enterprise historical data, supporting multi-source ingestion, a copy data lake, hot/cold tiering, full-text search, AI training-data management and compliant archiving — turning dormant historical data into a governable, searchable, reusable asset.
Built for real-world scenarios
Copy data lake
Unifies multi-source historical data into a governable, searchable copy data lake.
Hot/cold tiering
Auto-tiers storage by access heat, balancing performance and cost at EB scale.
Full-text search
Builds full-text indexes over archived data so old data stays instantly queryable.
AI training-data management
Governs high-quality, traceable historical datasets for model training.
See it in action
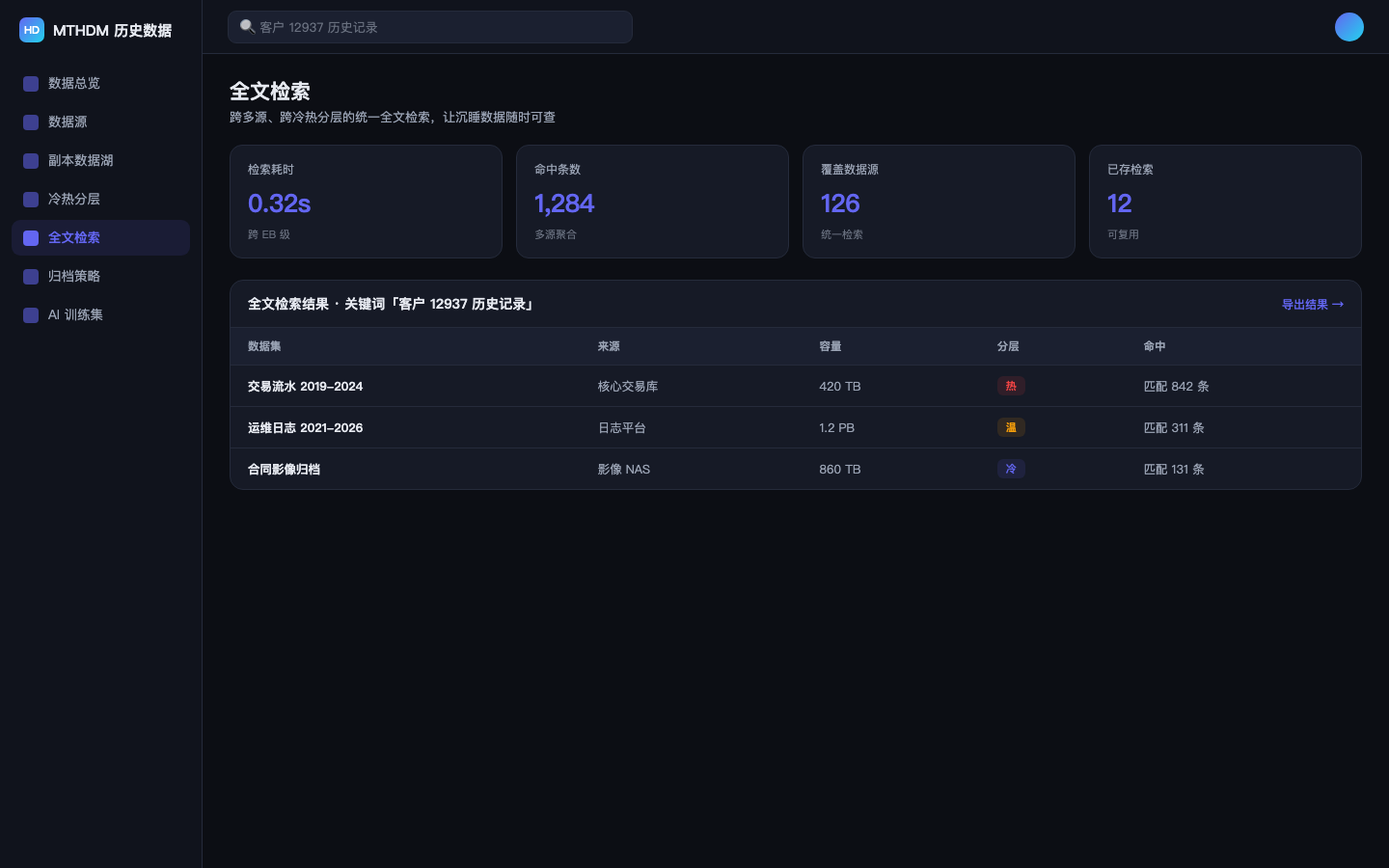
Data foundation architecture
Key advantages
About MeiTian Historical Data Management
What problem does MeiTian Historical Data Management solve?
It unifies, governs and indexes dormant historical data scattered across systems into a searchable, reusable copy data lake to meet EB-era storage and compliance challenges.
How does it balance performance and storage cost?
Through automatic hot/cold tiering — high-frequency data on fast tiers, low-frequency data on low-cost tiers.
Can historical data be used for AI training?
Yes — it provides AI training-data management with quality governance and traceability for high-quality model-training datasets.
Learn more about MeiTian Historical Data Management
Explore more capabilities, or browse the full MeiTian product matrix.